> ## Documentation Index
> Fetch the complete documentation index at: https://docs.learningcommons.org/llms.txt
> Use this file to discover all available pages before exploring further.
# Introduction
> Learn what evaluators are and how they help measure the quality of AI-generated educational materials through pedagogical alignment assessment.
export const EarlyReleaseBadge = () =>
Early release
;
export const EarlyAccessBadge = ({size = "md", children}) => {
return
{children == null || children === "" ? "Early access" : children}
;
};
## What evaluators do
Evaluators measure the quality of AI-generated educational content by assessing specific dimensions of text and identifying areas for improvement.
Evaluators help edtech developers reliably assess their LLM outputs and build evidence-based tools that reinforce student learning and whole child development.
| Evaluator family | Description |
| :-------------------------------------------------------------------- | :---------------------------------------------------------------------------------------- |
| [Literacy evaluators](/evaluators/literacy-evaluators/introduction) | Assesses the qualitative text complexity of a passage, often for a particular grade level |
| [Feedback evaluators](/evaluators/feedback-evaluators/introduction) | Assesses the quality of feedback on a student's response to a task goal |
| [Standards evaluators](/evaluators/standards-evaluators/introduction) | Assesses the alignment of educational content to standards |
## When to use evaluators
Whether you're testing, refining, or scaling, evaluators help you do it better and faster.
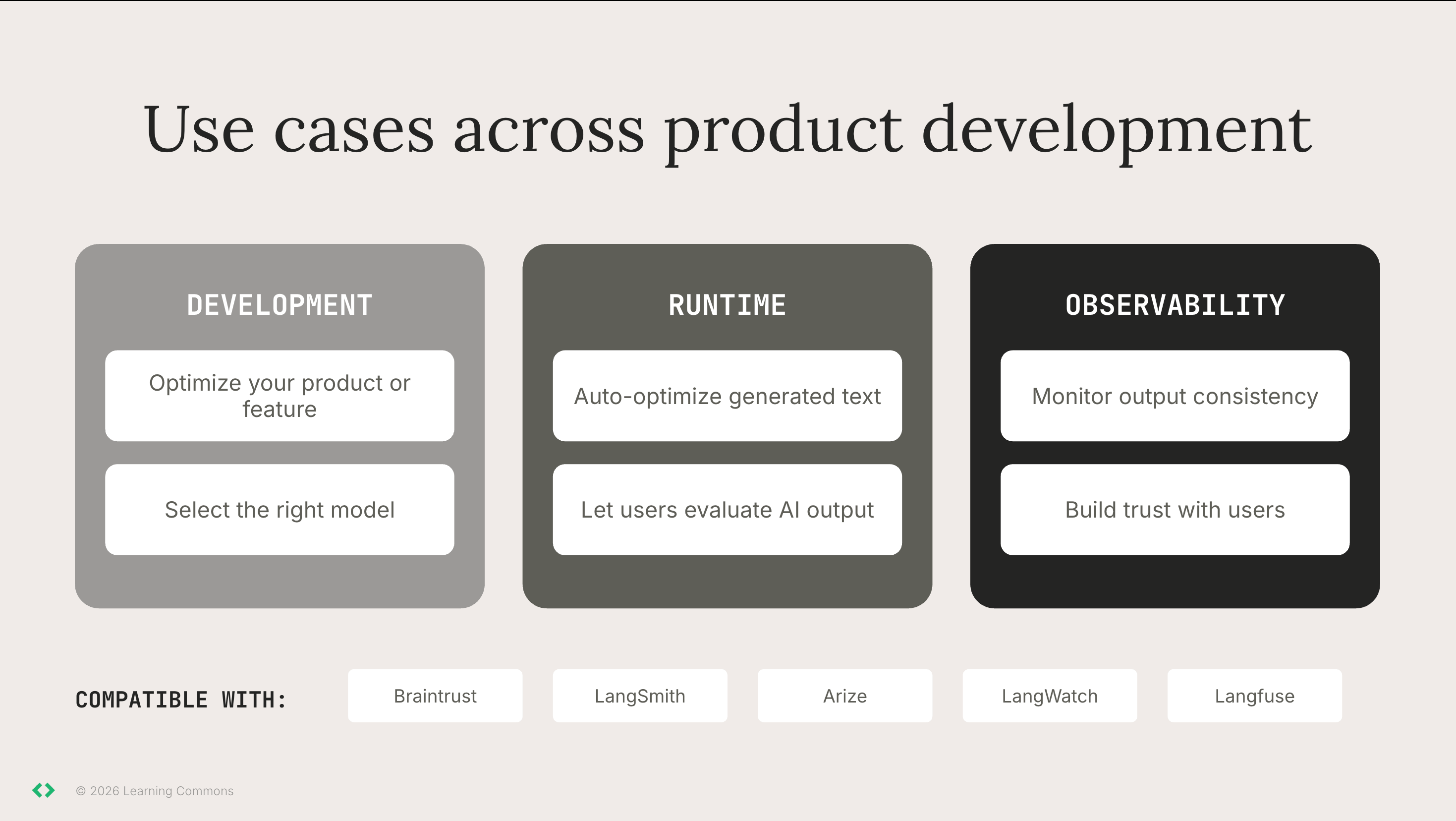 | Use case | Examples | Implementation |
| -------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Optimize your product or feature | You are building a vocabulary-focused feature – you want higher vocabulary difficulty and simpler sentence structure.
| Use case | Examples | Implementation |
| -------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Optimize your product or feature | You are building a vocabulary-focused feature – you want higher vocabulary difficulty and simpler sentence structure.
You are creating read-aloud support and want to deprioritize vocabulary complexity. | Set targets for vocabulary and sentence structure against grade level appropriateness. Run the [Sentence Structure Evaluator](/evaluators/literacy-evaluators/sentence-structure) and [Vocabulary Evaluator](/evaluators/literacy-evaluators/vocabulary) on your LLM outputs to confirm that they stay in acceptable ranges. |
| Select the right model | You need to compare new models on quality, speed, and cost before switching. | Create a *gold set* with expected scores for key parameters (e.g., grade level, topic, text type). Use evaluators as a standardized benchmark to monitor drift from your baseline. |
| Check your output at runtime | Your AI outputs may not always meet all your criteria (i.e., grade level appropriateness for K-3) | You can auto-optimize your AI-generated output or let users evaluate the output themselves. |
| Monitor output consistency | Your AI output starts to vary unexpectedly after model drift or small system updates. | Run regular regression tests on your LLM outputs and compare scores over time to ensure stable behavior. |
| Build trust with users | Districts and educators ask for evidence that your AI-generated content is high-quality and aligned with learning principles. | Share your evaluation process and results so stakeholders can see the rigor behind your system and trust that your outputs remain consistent and research-aligned. |
## How to access evaluators
| Access method | When to use |
| :------------------------------------------------------------------------------------ | :-------------------------------------------------- |
| [Evaluators Playground](/evaluators/getting-started/quickstart#evaluators-playground) | For a quick demo of how evaluators work |
| [SDK](/evaluators/getting-started/quickstart#sdk) | To integrate into your TypeScript or Python project |
| [Python notebooks](/evaluators/getting-started/quickstart#python-notebooks) | For quick prototyping |
## Our approach
Learning Commons collaborates closely with pedagogical experts to define, test, and build our evaluators.
We follow a research-informed process to develop evaluators that are firmly anchored in learning science:
 * We build alongside experts in learning science and rubric development (e.g. [Student Achievement Partners](https://learnwithsap.org/) ↗, [CAST](https://www.cast.org/) ↗, and [Achievement Network (ANet)](https://www.achievementnetwork.org/) ↗)
* We translate expert insight into ground-truth datasets that reflect real teaching and learning principles.
* We develop, validate, and ship software that evaluates text the way an expert would.
* We build alongside experts in learning science and rubric development (e.g. [Student Achievement Partners](https://learnwithsap.org/) ↗, [CAST](https://www.cast.org/) ↗, and [Achievement Network (ANet)](https://www.achievementnetwork.org/) ↗)
* We translate expert insight into ground-truth datasets that reflect real teaching and learning principles.
* We develop, validate, and ship software that evaluates text the way an expert would.